AI Production Scheduling Software: Types & How to Evaluate
The four types of AI in production scheduling software, what each delivers, the questions to ask vendors, and which fits your factory.
When AI appears in more and more scheduling tool descriptions, it can be hard to know what you’re actually looking at. The word covers a wide range of technologies: from rule engines with predefined logic to machine learning models trained on years of production data to reinforcement learning agents trained in simulation. The label tells you little about how the system makes decisions, what data it needs, or whether it fits your factory’s situation.
This article breaks down the main types of AI technology used in production scheduling software today. For each type, it explains what the underlying approach actually is, how vendors tend to describe it, what you can realistically expect from it, and where it runs into limits. The goal is to give production planners and operations teams a clearer basis for evaluating options.
Why “AI-powered” doesn’t tell you much on its own
The technology behind the label matters more than the label itself. Two scheduling tools that both describe themselves as “AI-powered” can behave completely differently when you’re using them, because the type of AI determines how the system generates a schedule, how it responds to disruptions, and what you need to have in place to have the software running.
It also determines how long deployment takes. A rule-based scheduler can often go live within weeks on a lean dataset. A machine learning model trained on historical data may need months of clean production records before it generates a useful schedule. A reinforcement learning system trained in simulation can operate without historical production data at all, because the learning happens entirely in a simulated factory environment.
Understanding which type of AI production scheduling software you’re looking at is the starting point for any honest evaluation.
Type 1: Rule-based and automated scheduling
Rule-based scheduling uses predefined logic to sequence production orders. The system applies dispatching rules such as first-in-first-out (FIFO), earliest due date (EDD), or shortest processing time (SPT), often combined with finite capacity constraints and heuristics that produce feasible plans quickly.
Vendors frequently describe this category as “intelligent scheduling,” “AI-driven planning,” or “automated scheduling.” The underlying technology is often not machine learning in any meaningful sense, but the generated plan can still look well-organized and consistent.
What you get: Fast setup, low data requirements, and plans that apply consistent logic across every shift. For stable, low-mix environments where constraints are well understood and disruptions are infrequent, a well-configured rule-based scheduler covers most of the planning work reliably.
Where it runs into limits: The rules don’t adapt. When machine priorities conflict, when a rush order arrives mid-morning, or when conditions change in a different way than the rules anticipate, the system has no way to recalibrate on its own. Planners typically step in and make manual adjustments. For a detailed comparison between rule-based and AI scheduling, this article explains the key differences.
Type 2: Mathematical optimization and APS engines
Advanced Planning and Scheduling (APS) systems built on mathematical optimization represent a step up from rule-based approaches. These tools use solvers such as Mixed Integer Programming (MIP), Genetic Algorithms (GA), or Simulated Annealing to search through large solution spaces and find schedules that score well on defined objectives.
Vendors often position these tools as “intelligent optimizers,” “AI-powered APS,” or “advanced scheduling engines.” Some of the most established production scheduling software in manufacturing falls into this category.
What you get: Genuine optimization within defined parameters. These tools can handle complex constraints and often find better sequences than pure rule-based approaches when the problem is well-specified. MIP solvers in particular can guarantee mathematical optimality on smaller, well-bounded scheduling problems.
Where it runs into limits: Mathematical optimization can become computationally slow as problem complexity grows. Very large or highly dynamic scheduling problems with frequent changes can push these solvers past their limits. Real-time replanning after disruptions tends to require significant recalculation, and the output quality depends heavily on how accurately the constraints are modeled upfront.
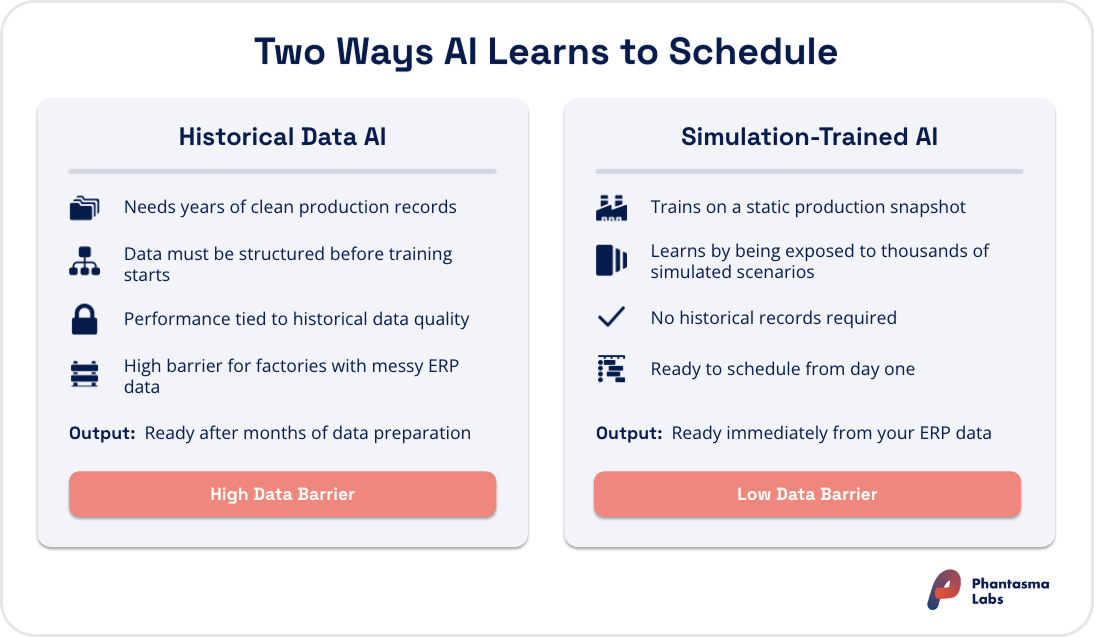
Type 3: Machine learning on historical production data
This category includes tools that train predictive or prescriptive models on historical production data. Supervised learning models can learn to predict cycle times, identify bottlenecks, or estimate demand patterns. The model then applies what it learned to support or generate scheduling decisions going forward.
Vendors describe this as “self-learning AI,” “data-driven scheduling,” “predictive scheduling,” or “adaptive AI.” In genuine implementations, the system does improve as more production data accumulates.
What you get: A system that adapts to your factory’s specific behavior, including the patterns in run times, seasonal demand shifts, and product families that share setup sequences. If your historical data is clean and your processes are stable, this type can add meaningful value to planning decisions. It falls under the broader umbrella of intelligent production scheduling in that it genuinely learns over time.
Where it runs into limits: Historical data is both the strength and the constraint of this approach. Training an effective model typically requires a significant volume of clean, consistent production records covering a stable operating period. If you have recently restructured lines, added new products, changed processes, or are running a factory without several years of reliable ERP or MES data, the training base may simply not be there. This approach also tends to struggle with scenarios outside its training distribution, such as new disruptions or rapid changes in product mix that haven’t appeared in the historical record.
Type 4: Reinforcement learning models trained in simulation
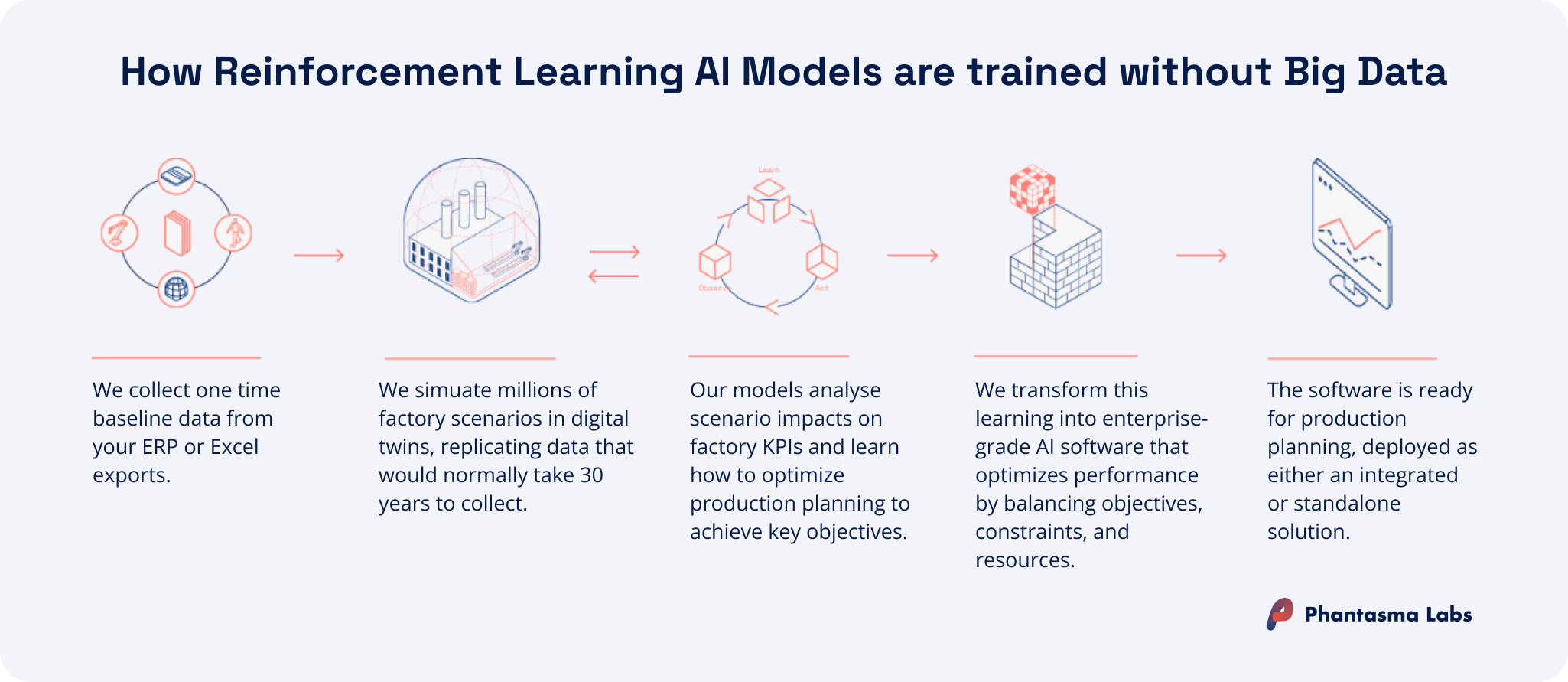
Reinforcement learning (RL) takes a fundamentally different approach to training. Instead of learning from historical production data, an RL agent learns scheduling policies by being confronted with millions of scenarios in a simulation model of the factory. The agent tries different sequencing and assignment decisions, receives feedback in the form of KPI scores, and gradually learns which decisions lead to better outcomes across a wide range of conditions.
What you get: A system that has been exposed to a wide range of scenarios in simulation before going live, including machine breakdowns, rush orders, shifting KPI priorities, and capacity changes. How well this translates to your specific environment depends on how well the simulation reflects your actual constraints, but the approach doesn't require years of historical data to start learning. Deployment timelines tend to be shorter than with historical-data-based systems, and KPI priorities can typically be adjusted without retraining from scratch.
Where it runs into limits: RL-based systems require a well-specified simulation model of the factory. The quality of the simulation directly influences what the agent learns. If the simulation does not accurately capture the real shop floor constraints and dynamics, the learned policies may not transfer cleanly to live operations.
Hybrid approaches: what most tools actually are
In practice, clean category boundaries don’t always match how tools are built. Many automated production scheduling products combine approaches: OR optimization for the main planning horizon, dispatching rules for day-of sequencing and ML models for demand or cycle time prediction.
When a vendor describes their tool as “AI-powered,” it’s often a combination. What matters for evaluation is understanding which parts of the scheduling decision are actually being optimized or learned, and which are still executing fixed logic. Asking directly how the system was trained usually clarifies this quickly.
A note on generative AI and LLM-based interfaces: natural language inputs and chat-based planning assistants are increasingly appearing in AI scheduling software manufacturing vendors offer. These are interface features, not scheduling AI. The underlying scheduling engine still uses one of the types above. The quality of any schedule still depends entirely on what the engine underneath can actually compute.
Three questions to ask any vendor
Understanding the categories makes vendor conversations much more concrete. Three questions will quickly clarify what you’re actually looking at when evaluating AI powered scheduling tools.
1. How was the AI trained?
Ask the vendor to explain specifically how the AI was trained — not what it can do, but how it actually learned to make scheduling decisions. The answer tells you which type of system you're dealing with, which directly determines what data you'll need to provide, how long deployment will take, and what the system can and can't adapt to.
2. What data do you need from us before we can go live?
Some AI production scheduling software requires years of clean production history before it can generate a useful schedule. Others need only current orders, routings, and machine calendars. The difference has a direct impact on how quickly you can get to a real pilot.
3. When our planning situation changes due to new priorities, new products, different volumes, how does the system adapt?
This is where rule-based systems show their limits. A system built on fixed logic can only apply what it has been configured for. When the planning situation changes, someone has to manually update the rules. A system that genuinely learns adapts to new conditions automatically. If the vendor's answer involves manual reconfiguration, parameter updates, or looping in the implementation team every time something changes, the system isn't genuinely adaptive, regardless of how it's described in the sales materials.
Which type fits your factory
The right choice depends on your factory’s specific combination of complexity, data availability, and daily planning challenges. The table below gives a starting orientation for production scheduling software comparison.
Stable, low-mix production with few daily disruptions: Type 1 or 2 is often sufficient
Complex environment with several years of clean ERP/MES data: Type 3 (ML on historical data)
High-mix, frequent disruptions, limited or unreliable historical data: Type 4 (RL trained in simulation)
Already running APS, struggling with dynamic replanning: Type 4 or hybrid approach
If you’re unsure where your factory falls, a structured assessment can help clarify what data you already have, what level of complexity you’re working with, and where the biggest scheduling constraints sit. The AI scheduling readiness check walks through the key questions in a practical way and helps you understand which type of AI scheduling approach is actually a fit for your operations. Or if you'd prefer to talk through your specific setup, get in touch — we're happy to help you figure out where to start.
Key Takeaways
The AI label tells you little on its own. The technology behind it determines data requirements, deployment time, and how the system performs when planning parameters change.
Type 1 (rule-based) is fast and reliable but doesn’t adapt when conditions change or priorities conflict.
Type 2 (mathematical optimization / APS) produces genuine schedule optimization within defined parameters but can be slow and brittle in highly dynamic environments.
Type 3 (ML on historical data) learns from your factory’s patterns but requires a significant base of clean, stable production records and struggles with novel scenarios.
Type 4 (RL trained in simulation) handles disruption well and doesn’t require historical production data, but depends on a well-specified simulation model of the factory.
Most AI production scheduling software is a hybrid. GenAI and LLM-based interfaces are a UI layer, not scheduling intelligence.
FAQs on this Topic
What are the different types of AI used in production scheduling software?
What is the difference between machine learning and reinforcement learning in AI-powered production scheduling?
How do I know which type of AI scheduling fits my factory?
What is reinforcement learning and how is it used in production scheduling?
Want to stay up to date about how AI is transforming the manufacturing industry?
Subscribe to our newsletter for a monthly wrap up of the latest news and industry trends combined with deep dives and practical guides around AI, production planning and smart manufacturing.
Thanks for subscribing! We’ll keep you up to date with monthly insights on smart manufacturing.
Oops! Something went wrong while submitting the form.
Is AI scheduling a fit for your factory?
The readiness check helps you assess whether AI production scheduling fits your environment in 5 minutes.




.png)